Introducción a Docker
Table of contents
Problema
Antes que nada, recordemos como es el ciclo de vida del desarrollo de software. En un esquema típico podemos ver las siguientes etapas:
- Ciclo de vida de la aplicación:
- Desarrollo: Durante el desarrollo, es común que dos o mas desarrolladores deban colaborar sobre el mismo código. Necesitan entornos idénticos para poder desplegar la misma aplicación en sus computadoras.
- Integración: Algunas empresas utilizan otro entorno separado donde se integran todas las funcionalidades o servicios desarrollados por separado. En este entorno se resuelve cualquier problema integración.
- Testing: Son servidores donde se despliega el sistema para hacer los controles de calidad previos a la entrega.
- Pre - producción: Una vez aprobado desarrollo, se despliegan los cambios en un ambiente similar al de producción, donde se pueden hacer los últimos ajustes.
- Producción: Servidores donde se aloja la aplicación cuando ya esta disponible al publico.
Cada uno de estos entornos es distinto, y puede que hayan problemas de compatibilidad con algunas dependencias en alguno de ellos. Ademas, es normal que sea gente distinta la que debe desplegar las aplicaciónes en cada uno.
Los desarrolladores deben escribir instrucciones claras indicando todas las dependencias necesarias y sus versiones, ademas de cualquier otro paso necesario para que la gente encargada de operaciones pueda hacer los despliegues.
Ademas, hay que tener en cuenta que todas estas dependencias, herramientas o sistemas operativos deben ser actualizadas, y aveces reemplazadas por otras.
Todo esto genera mucha perdida de tiempo, y es normal que a pesar de todo se tengan problemas en cualquiera de los puntos y se tengan que hacer rollbacks constantes.

Virtual Machines
Las máquinas virtuales han existido desde la década de 1960, aunque la tecnología ha evolucionado significativamente desde entonces. En los primeros días de las VM, se utilizaban principalmente para la investigación y el desarrollo de software. A medida que las computadoras se hicieron más potentes y los sistemas operativos más complejos, se hizo más difícil para los desarrolladores probar su software en diferentes configuraciónes de hardware. Las VM resolvieron este problema permitiendo a los desarrolladores emular diferentes entornos de hardware y software en una sola máquina física. A lo largo de los años, las VM se han vuelto más eficientes y fáciles de usar, y se han convertido en una herramienta común para la virtualización de servidores y la creación de ambientes de pruebas.
Una máquina virtual (VM, por sus siglas en inglés) es un ambiente de computación emulado que se comporta como una computadora real y que se puede usar para ejecutar software que no funciona en el sistema operativo del host.
En una VM, se puede instalar un sistema operativo completo y cualquier software que se necesite para ejecutar una aplicación específica.
Las VM se ejecutan en una capa de software de virtualización, que se interpone entre el hardware físico y el sistema operativo del host.
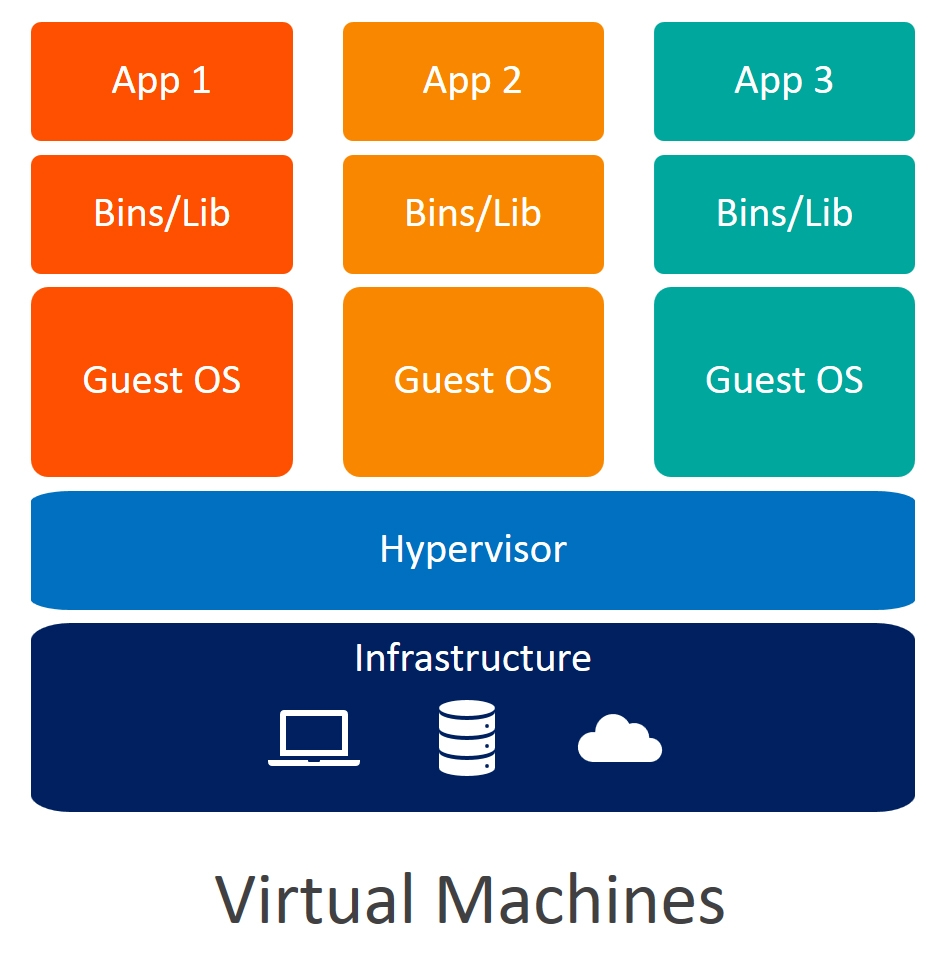
Las VM proporcionan un alto nivel de aislamiento y seguridad, ya que cada VM se ejecuta en su propio ambiente aislado. Sin embargo, también son más pesadas en términos de recursos de hardware, ya que cada VM necesita su propia copia del sistema operativo y cualquier software necesario.
Este sistema resuelve todos los problemas explicados mas arriba, ya que podemos tener nuestra aplicación funcionando en una VM, con un sistema operativo y dependencias compatibles. Esta VM luego puede ser fácilmente compartida entre desarrolladores o montada en otros servidores, sin importar la configuración del hardware o software.
Sin embargo, las VM requieren montar todo un sistema operativo nuevo, dentro del sistema operativo del host. Esto requiere mucho espacio y consume muchos recursos, pudiendo alcanzar varios GB para cada VM. Si queremos tener varias aplicaciónes corriendo, cada una dentro de su propio ambiente, esto se vuelve casi insostenible.
Que es un contenedor?
Los contenedores han sido una tecnología en evolución desde la década de 2000. Los primeros contenedores se crearon en Linux utilizando herramientas como LXC y cgroups. Estos contenedores permitían la virtualización a nivel de sistema operativo, lo que permitía a los desarrolladores empaquetar aplicaciónes con sus dependencias en un solo entorno. Sin embargo, estos contenedores eran muy limitados en términos de portabilidad, lo que dificultaba su uso en diferentes entornos.
En el 2013, Docker fue creado y rápidamente se convirtió en el estándar de facto para los contenedores. Docker mejoró significativamente la portabilidad de los contenedores al permitir que las imágenes se ejecutaran en cualquier sistema operativo que soporte Docker, independientemente de la configuración del hardware o el sistema operativo.
En términos generales, un contenedor es una forma de empaquetar una aplicación con todas las dependencias y librerías, incluyendo sus archivos de configuración, pero sin necesidad de instalar un sistema operativo como en una VM.
Esto hace que sea fácil desplegar aplicaciónes, independientemente de la configuración del hardware o el sistema operativo.
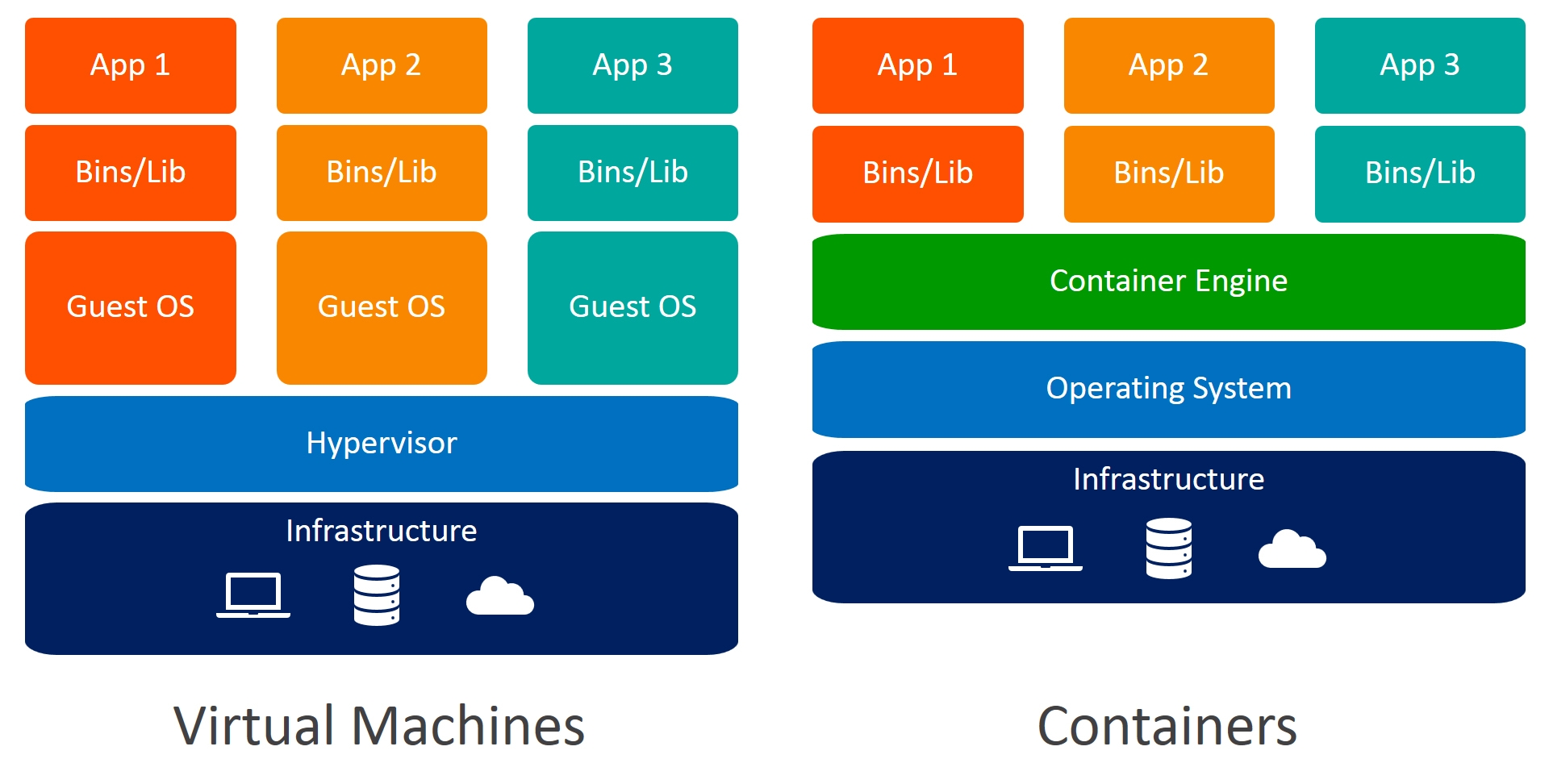
A diferencia de las VMs, los contenedores necesitan un motor de algún tipo (dependiente de la tecnología de contenerizacion). Este motor funciona como interfaz entre el contenedor y el hardware, y se encarga de desplegarlo y gestionar los recursos necesarios.
Entre las ventajas que obtenemos al utilizar contenedores podemos citar:
- Portabilidad: Al no necesitar un sistema operativo, el paquete resultante es muy liviano, y al contener toda la información necesaria se puede compartir con facilidad.
- Eficiencia y uso de recursos: La arquitectura de los contenedores permite un mejor uso de los recursos, y compartirlos entre contenedores. Esto facilita el despliegue de multiples aplicaciónes o escalar la misma en el mismo servidor.
- Versionado: Para construir un contenedor, necesitamos empezar por un archivo que describe lo que queremos hacer y como, en el caso de Docker esto sera un docker file. Esto puede versionarse para mantener un control de cambios.
- Fácil distribución: Los contenedores pueden almacenarse en repositorios privados o públicos, como Docker Hub.
Con esta tecnología, todo el problema del despliegue y la compatibilidad de las dependencias se resuelve con un par de comandos.
Docker Desktop
A partir de aca podemos pasar a la practica, y vamos a ir explicado los demás conceptos a medida que avanzamos.
Docker Desktop es una herramienta que permite desplegar y administrar contenedores e imágenes de Docker en un entorno de escritorio. Permite acceder al sistema de archivos y también incluye herramientas como Docker Compose y la CLI de Docker. Es nativo en Windows, pero también está disponible para Mac y Linux.
Para descargar Docker Desktop, debes seguir los siguientes pasos:
- Visita este enlace: https://www.docker.com/products/docker-desktop
- Si utilizas Windows, haz clic en “Download for Windows” y si utilizas Mac, haz clic en “Download for Mac”. Si utilizas Linux, elige tu distribución en la lista desplegable.
- Si eres usuario de Windows o Mac, deberás crear una cuenta de Docker. Si ya tienes una cuenta, inicia sesión. Si eres usuario de Linux, no es necesario crear una cuenta.
- Descarga el instalador y sigue las instrucciones que aparecen en pantalla para instalar Docker Desktop en tu equipo.
Una vez que tengas Docker Desktop instalado, podrás comenzar a utilizar Docker en tu máquina local.
Es posible que tengas que instalar una actualización del WSL2 en Windows. Si es el caso asegurate de seguir los pasos 4 y 5 del tutorial que te indica el mensaje.
En este tutorial vamos a trabajar con la terminal, asi que no sera necesario que usemos esta interfaz grafica. Pero para poder hacer todos los pasos siguientes sera necesario que Docker Desktop este corriendo.
Docker Hub
Docker Hub es un repositorio de imágenes de Docker que permite a los usuarios almacenar y compartir imágenes de contenedores. Los usuarios pueden buscar y descargar imágenes de Docker desde el Docker Hub, y también pueden cargar sus propias imágenes para compartir con la comunidad.
Para empezar a utilizar Docker Hub podemos ir a esta URL: https://hub.docker.com/.
Una vez ahi, bajando un poco en la pagina podemos ver que nos ofrece una gran cantidad de imágenes que podremos descargar y utilizar:
Imágenes
Una imagen es el empaquetado propio de una aplicación o dependencia. Es básicamente una instantánea de una aplicación y sus dependencias o de una imagen base.
En Docker, un contenedor es un conjunto de imágenes que conforman todo lo necesario para el funcionamiento de una aplicación o servicio. Un contenedor está formado por capas de imágenes.
Asegurate de que docker desktop este corriendo, y en la terminal escribí lo siguiente:
docker images
El comando docker images muestra una lista de las imágenes de Docker que están disponibles en su sistema.
La primera vez que ejecutamos el comando, deberíamos ver una tabla vacía, porque aun no tenemos imágenes descargadas.
El siguiente paso, es descargar una imagen. Vamos a empezar por descargar una imagen de Node. Ejecuta el comando:
docker pull node
para empezar a descargar la imagen.
Cuando solo ejecutamos el comando docker pull node, vamos a descargar la ultima version de node disponible en docker hub. También podemos hacer docker pull node: 18, para desargar la version 18 de node.
Docker empezara a descargar las diferentes imágenes que a su vez componen la imagen de node una a una, y al finalizar deberíamos ver algo como esto:
PS C:\Users\fersz> docker pull node
Using default tag: latest
latest: Pulling from library/node
1e4aec178e08: Pull complete
6c1024729fee: Pull complete
c3aa11fbc85a: Pull complete
aa54add66b3a: Pull complete
9e3a60c2bce7: Pull complete
17901317c11c: Pull complete
cd2a67b2d442: Pull complete
0871896c2370: Pull complete
c5692662363a: Pull complete
Digest: sha256:d903b23148dccca63152cb2bdf6fdfa062842dcce49f0d45558ca06a8ab14598
Status: Downloaded newer image for node:latest
docker.io/library/node:latest
En la terminal se nos indica que al no especificar una etiqueta de version, se procede con la etiqueta latest, que significa que vamos a descargar la ultima version disponible.
Seguidamente, volvamos a hacer docker images, y deberiamos ver esto:
REPOSITORY TAG IMAGE ID CREATED SIZE
node latest 2201f1d2b46f 4 days ago 999MB
Esta vez, la tabla lista la imagen que descargamos, si etiqueta (latest), un ID de la imagen y los demas datos.
Ahora vamos a instalar una segunda imagen, haciendo docker pull mongo. Al volver a correr docker images deberiamos ver lo siguiente:
REPOSITORY TAG IMAGE ID CREATED SIZE
node latest 2201f1d2b46f 4 days ago 999MB
mongo latest a440572ac3c1 3 weeks ago 639MB
Creando un contenedor
Ya tenemos imagenes descargadas, ahora, para crear nuestro primer contenedor podemos hacer simplemente lo siguiente:
docker create mongo
Esto simplemente crea un contenedor en base a la imagen que le especificamos, en este caso “mongo”
Al correr el comando docker nos devuelve un ID, esto lo vamos a necesitar para gestionar el contenedor.
docker create es una forma abreviada del comando docker container create
Ahora el contenedor esta creado, pero todavía no esta corriendo.
Para desplegar el contenedor, tomamos el id que nos devolvió el comando anterior y hacemos:
docker start <containerID>
Si no hay errores, esto nos devuelve nuevamente el mismo ID, y deberíamos tener algo asi en la consola:
PS C:\Users\fersz> docker start 979e80d73d85
979e80d73d85
El comando docker ps muestra una lista de los contenedores de Docker que están en ejecución en su sistema. Con esto podemos verificar que nuestro contenedor esta corriendo:
PS C:\Users\fersz> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
979e80d73d85 mongo "docker-entrypoint.s…" 9 minutes ago Up 2 minutes 27017/tcp relaxed_shockley
La tabla que devuelve el comando docker ps muestra las siguientes columnas:
- CONTAINER ID: El ID del contenedor.
- IMAGE: La imagen utilizada para crear el contenedor.
- COMMAND: El comando que se ejecuta en el contenedor.
- CREATED: La fecha en que se creó el contenedor.
- STATUS: El estado actual del contenedor (corriendo o detenido).
- PORTS: Los puertos asignados al contenedor.
- NAMES: El nombre asignado al contenedor. Si no se especificó uno, se le asigna uno aleatorio generado por Docker.
El puerto asignado es el puerto del contenedor, no de nuestra maquina. Veremos mas sobre esto en la siguiente sección.
Podemos detener el contenedor haciendo:
docker docker start <containerID>
y luego volvemos a verificar la salida de docker ps. Al hacerlo vemos que ya no se lista el contenedor, porque este comando solo muestra los contenedores que están activos. Para ver el estado de nuestro contenedor podemos hacer:
docker ps -a
Al hacerlo vemos esta tabla:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
979e80d73d85 mongo "docker-entrypoint.s…" 17 minutes ago Exited (0) 7 seconds ago relaxed_shockley
Ahora vamos a eliminar el contenedor. Para esto también podemos usar el ID como venimos haciendo, pero también podemos usar el nombre (NAME) del contenedor. Si nos fijamos en la tabla vemos que el nombre en este caso es “relaxed_shockley”. Este es un nombre aleatorio asignado por Docker. Hagamos:
docker rm relaxed_shockley
Si volvemos a listar los contenedores vemos que ya no tenemos ninguno.
Nombre del contenedor.
Ahora vamos a volver a crear el contenedor de mongo, pero esta vez vamos a darle un nombre, ya que manejarnos con el ID puede volverse muy complicado.
Hagamos en la consola:
PS C:\Users\fersz> docker create --name mongo_ppy mongo
ab67fd3ddc9f123a7c26ba6be1e073fda965d851294ee3915dbfb0e0abed36dc
Si funciona, nuevamente nos devuelve un ID. Pero esta vez al hacer docker ps -a vemos que la columna NAME de la tabla ahora muestra el nombre mongo_ppy.
Podemos correr el contenedor haciendo:
docker start mongo_ppy
Port Mapping
Ahora ya podemos ver que el contenedor de mongo se encuentra corriendo:
PS C:\Users\fersz> docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ab67fd3ddc9f mongo "docker-entrypoint.s…" 3 minutes ago Up 40 seconds 27017/tcp mongo_ppy
Sin embargo, todavía no podemos interactuar con el contenedor, porque si bien en la tabla vemos que el contenedor esta corriendo sobre el puerto 27017/tc, esto es un puerto del contenedor (recordemos que esto se encuentra virtualizado), y en realidad no tenemos forma de acceder desde afuera.
El port mapping o mapeo de puertos es una técnica utilizada para permitir que los contenedores se comuniquen con el mundo exterior. Cuando se ejecuta un contenedor, se pueden asignar puertos en el host para que se comuniquen con los puertos del contenedor.
Por ejemplo, un contenedor de base de datos puede tener su puerto 27017 expuesto, pero si un usuario quiere interactuar con la base de datos desde fuera del contenedor, necesita un puerto en el host para hacerlo. El mapeo de puertos permite que el usuario se conecte a un puerto en el host que se redirige al puerto del contenedor, permitiendo así la comunicación entre el contenedor y el mundo exterior.
Para asignar un puerto en el host al puerto del contenedor, se utiliza el comando -p al crear el contenedor. Por ejemplo, si queremos asignar el puerto 27017 del contenedor al puerto 27017 del host, usaríamos el siguiente comando:
docker run -p 27017:27017 mongo
Con esto, cualquier solicitud que llegue al puerto 27017 del host se redirigirá al puerto 27017 del contenedor, permitiendo la comunicación entre ambos.
Para hacer esto, vamos a necesitar detener el contenedor actual, y borrarlo:
PS C:\Users\fersz> docker stop mongo_ppy
mongo_ppy
PS C:\Users\fersz> docker rm mongo_ppy
mongo_ppy
PS C:\Users\fersz> docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
Ahora podemos volver a crear el contenedor de la siguiente manera:
PS C:\Users\fersz> docker create -p27017:27017 --name mongo_ppy mongo
5225452c6fda9955dc5b15fad1962fe30840862d9cf1d6458d11302bce344423
PS C:\Users\fersz> docker start mongo_ppy
mongo_ppy
PS C:\Users\fersz> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5225452c6fda mongo "docker-entrypoint.s…" 20 seconds ago Up 9 seconds 0.0.0.0:27017->27017/tcp mongo_ppy
Al hacer esto, puede que nuestro sistema operativo nos pida algunos permisos.
Con esto, el contenedor se encuentra publicado en el puerto 0.0.0.0:27017 de nuestra maquina.
Si nosotros fuéramos a hacer docker create -p27017 --name mongo_ppy mongo, Docker decidirá por su cuenta en que puerto publicar el contenedor.
Docker run
docker run es un comando de Docker que se utiliza para crear y ejecutar un contenedor a partir de una imagen de Docker. Al ejecutar docker run, Docker descarga la imagen si aún no está disponible localmente, y luego crea y ejecuta un contenedor utilizando la configuración especificada en el comando. Con docker run, puedes especificar varios parámetros, como la imagen a utilizar, el puerto a exponer, y los comandos que se deben ejecutar dentro del contenedor.
Este comando combina los comandos docker pull, docker create y docker start, por lo que podemos hacer todo lo anterior con un solo comando:
docker run --name mongo_2 -p27017 -d mongo
Esto va a buscar una imagen de mongo, si no la encuentra la va a descargar. Seguidamente va a crear un contenedor con el nombre mongo_2, y lo va a publicar en un puerto disponible que encuentre docker.
No se puede usar docker run para correr contenedores que ya fueron creados, ya que este comando siempre creara un contenedor nuevo.
Desplegando una aplicación
Vamos a pasar a un ejemplo mas complejo, desplegando una aplicación entera.
Para esto, vamos a prestar un repositorio hecho por el canal HolaMundo de Youtube, y explicado en este video: https://www.youtube.com/watch?v=4Dko5W96WHg&t=2446s&ab_channel=HolaMundo.
Lo primero que tenemos que hacer es descargar el repositorio https://github.com/nschurmann/mongoapp-curso-docker. Nos basta con descargar un zip de extraerlo, pero también podemos clonar el repo para que nos quede el proyecto en nuestra cuenta de GitHub.
Esta es una aplicación sencilla hecha con NodeJs, que se comunica con una base de datos no relacional, MongoDB, a traves de una librería llamada mongoose. Los detalles de la aplicación no son importantes en este punto.
Conectando la aplicación a un contenedor.
En primer lugar, la aplicación necesita conectarse a una base de datos. Para esto, vamos a crear un contenedor de mongo DB.
Se recomienda eliminar todos los contenedores e imágenes que creamos previamente, para empezar con un entorno limpio.
Primero, tenemos que descargar la imagen de mongo haciendo docker pull mongo.
Ahora, una cosa que no hicimos anteriormente fue configurar el contenedor. Para que podamos conectarnos a la base de datos, necesitamos configurar algunas variables de entorno. Podemos encontrar todas las instrucciones en la pagina de docker hub. Cada contenedor tendrá una configuración diferente.
Para este caso, nuestra base de datos tiene un usuario y contraseña, y la aplicación en NodeJs, debe conectarse teniendo esto en cuenta.
Miremos la linea 11 en el archivo index.js:
mongoose.connect('mongodb://ppy:password@localhost:27017/miapp?authSource=admin')
podemos ajustar esta URL con el nombre de usuario y el password que queramos. En mi caso, el nombre de usuario es ppy y el password es password. Hay que tener cuidado con no cambiar nada mas en la URL.
Podemos copiar la linea que tenemos mas arriba y reemplazarla en el código fuente.
Podemos dejar esa linea como estaba, en ese caso el usuario sera nico, y el password
Ahora si podemos crear el contenedor haciendo:
docker create -p27017:27017 --name mongo_ppy -e MONGO_INITDB_ROOT_USERNAME=ppy -e MONGO_INITDB_ROOT_PASSWORD=password mongo
Este comando crea el contenedor mongo_ppy, mapeando el puerto 27017 del contenedor al puerto 27017 del computador “host”. Hasta ahi es lo mismo que hicimos antes.
Al escribir -e estamos agregando una variable de entorno a la configuración del contenedor. En este caso agregamos dos variables que definen el nombre de usuario y la contraseña para la base de datos.
Para que esto funcione tenemos que asegurarnos de que el nombre de usuario, la contraseña y el nombre del contenedor coincidan con lo que tenemos en index.js de nuestra app.
Podemos arrancar el contenedor y verificar que este corriendo:
PS C:\Users\fersz> docker start mongo_ppy
mongo_ppy
PS C:\Users\fersz> docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b721e415c702 mongo "docker-entrypoint.s…" 25 seconds ago Up 2 seconds 0.0.0.0:27017->27017/tcp mongo_ppy
Levantando la aplicación
Para levantar la aplicación lo primero que tenemos que tener en cuenta es que necesitamos tener Node instalado.
Ademas de eso, necesitamos instalar las dependencias necesarias. Las mismas (express y mongoose) se encuentran en el archivo package.json, asi que basta con abrir la terminar en la carpeta de la aplicación y correr el comando npm install.
Una vez instaladas las dependencias, y todavia ubicados en la carpeta, podemos correr node index.js para levantar la aplicación:
C:\Users\...\mongoapp-curso-docker-main>node index.js
listening...
Vemos que se imprime en consola el mensaje listening..., que esta en la ultima linea del archivo index.js, y nuestra aplicación se encuentra escuchando en el puerto 3000.
Si vamos un browser y en la barra de direcciones vamos a localhost:3000, deberíamos ver en el browser un array vacío ([ ]).
Ahora podemos navegar, siempre en el browser, a localhost:3000/crear. Esto va a ejecutar el código en la linea 18 de la app, y va a crear un registro en la base de datos. En el browser deberíamos ver “OK”.
Finalmente, podemos volver a consultar la base de datos volviendo a navegar a localhost:3000:

Con esto confirmamos que logramos conectarnos a la base de datos, escribir y leer.
Hasta aca logramos algo muy interesante. La aplicación de Node es estándar, pero la base de datos esta corriendo en un contenedor, sin necesidad de que instalemos Mongo en nuestra maquina y configuremos un servicio para exponer la base de datos. Resolvimos todo con un par de comandos de docker.
El siguiente paso sería empaquetar la aplicación de node para que también corra en un contenedor.